
Stop me if you’ve heard this one before: You ask an AI to refactor a legacy Python script. It spits out code that looks perfect. You copy-paste it. It fails. You paste the error message back. It apologizes, gives you a new snippet. That fails too. An hour later, you’re manually rewriting the whole thing, wondering why you even bothered.
That was the “Chatbot Era.” It ended yesterday.
We are now entering the “Agent Era,” and the landscape has shifted violently. We aren’t just comparing text generators anymore; we are comparing autonomous engineers that can live inside your terminal, execute code, and fix their own mistakes. The decision facing every technical founder and lead dev right now isn’t about which model writes better poetry—it’s the architectural choice of Codex 5.3 vs Claude Opus 4.6.
If you are paralyzed by the fragmentation of the market, you aren’t alone. Do you restructure your team around OpenAI’s blistering speed and terminal proficiency, or do you pivot to Anthropic’s deep-reasoning “slow thinking” stack? Let’s tear down the specs, the benchmarks, and the messy reality of production AI.
The Paradigm Shift: From “Typing” to “Doing”
To understand the difference between Codex 5.3 vs Claude Opus 4.6, we have to look at “The Pelican Incident.”
It begins with a developer debugging a Pelican static site generator error. In the old world (GPT-4o), the AI would suggest a fix, the dev would run it, fail, and report back. The loop took 4 hours.
With Codex 5.3, the workflow evaporated. The developer gave the agent terminal access. Codex 5.3 didn’t just suggest code; it ran the build, saw the error, modified the pelicanconf.py, ran the build again, realized a dependency was missing, installed it, and deployed. Total time: 5 minutes.
This is the core differentiator. We are moving from “Human-in-the-Loop” to “Human-on-the-Loop.”
The Contenders: A Tale of Two Philosophies
Codex 5.3: The Speed Demon
Released by OpenAI as a direct successor to the GPT-4o lineage, Codex 5.3 is built for velocity. It is designed to be the “10x Engineer” that breaks things fast and fixes them faster.
- Core Strength: Recursive self-correction. It assumes its first draft is wrong and proactively tests it.
- The Killer Feature: Native Terminal Proficiency. It doesn’t just output text; it interacts with the OS.
- Vibe: The caffeine-fueled senior dev who types 100wpm and ships to prod on Friday.
Claude Opus 4.6: The Architect
Anthropic has taken a different route. Opus 4.6 is the “Deep Thinker.” It has a massive context window and a slower, more deliberate inference chain.
- Core Strength: One-shot accuracy. It tries to get the architecture right before writing a single line of code.
- The Killer Feature: Massive Context Coherence. It can hold your entire repo in its head without hallucinating variable names from three files ago.
- Vibe: The Staff Engineer who stares at the whiteboard for 3 hours and then writes the perfect solution in 10 minutes.

The Benchmarks: OSWorld, Terminal, and Reality
Everyone loves a good chart, but in the battle of Codex 5.3 vs Claude Opus 4.6, standard text benchmarks are irrelevant. We need to look at agency—the ability to act.
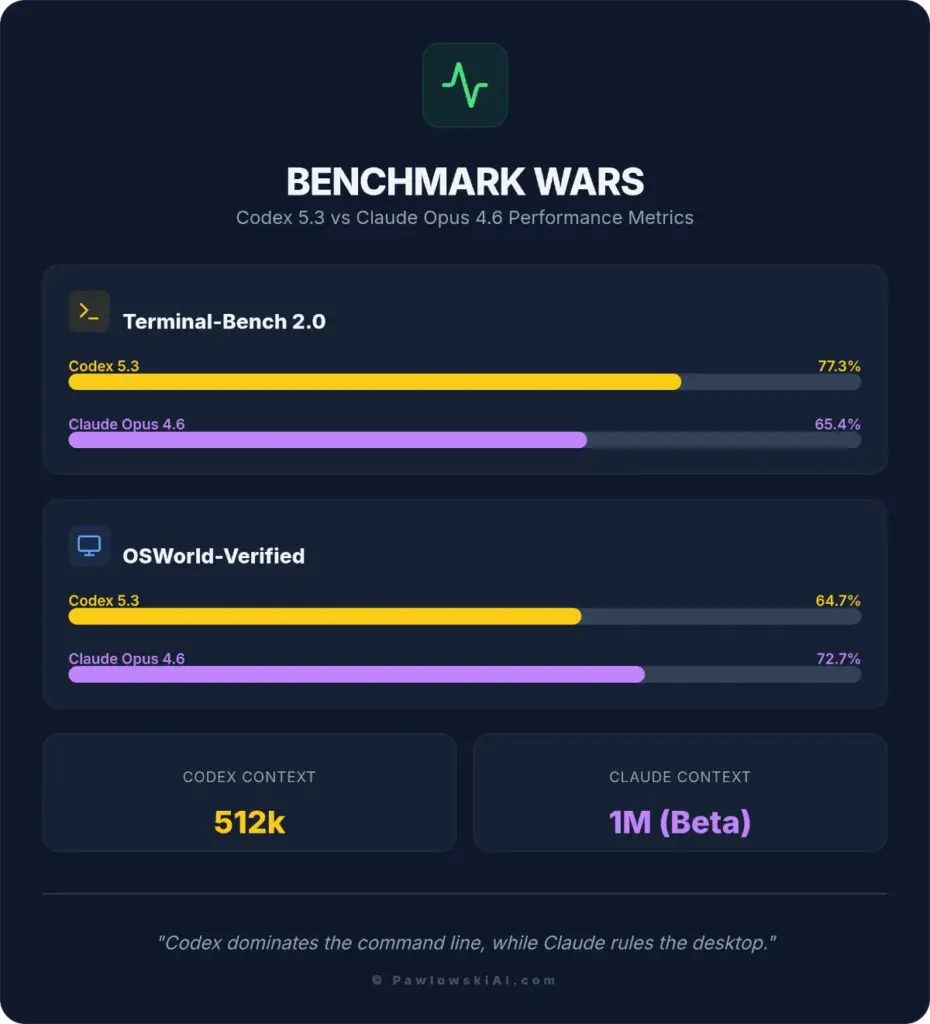
We pulled the latest confirmed metrics from the Content Blueprint to show exactly where the split lies.
| Metric | Codex 5.3 | Claude Opus 4.6 | The Takeaway |
| Terminal-Bench 2.0 | 77.3% | 65.4% | Codex dominates the command line (bash, git, docker). |
| OSWorld-Verified | 64.7% | 72.7% | Claude is actually better at navigating GUIs and general desktop tasks. |
| Context Window | 512k | 1M (Beta) | Claude can hold your entire repo; Codex needs RAG. |
The “Vibe Check”
The numbers tell a specific story: Codex 5.3 is a Terminal specialist, while Claude Opus 4.6 is a Desktop generalist.
If your workflow lives in a headless environment—SSHing into servers, running npm install, managing Docker containers—Codex 5.3 is the clear winner. Its 77.3% score on Terminal-Bench translates to a “twitchy,” responsive feel. It writes code, runs it, fails, and fixes it before you can blink.
Claude Opus 4.6 feels “heavy” but incredibly robust. Its superior OSWorld score (72.7%) means it handles visual tools, browser navigation, and file management better, but it lacks that raw, aggressive speed in the CLI.
OpenAI unveils GPT-5.3-Codex, which can tackle more advanced and complex coding tasks, marking a significant departure from simple “autocomplete” functions to genuine agentic behavior.
Integration: How They Fit in Your Stack
Scenario A: The CI/CD Pipeline
If you want an agent to sit in your GitHub Actions, monitor failed builds, and automatically submit PRs to fix them, Codex 5.3 is the winner. Its ability to read the terminal output, understand the specific error code, and iterate quickly makes it ideal for the dirty work of DevOps.
Scenario B: Greenfield Architecture
If you are asking an AI to “Scaffold a microservices architecture for a fintech app using Go and gRPC,” Claude Opus 4.6 takes the crown. Codex 5.3 might rush into coding the first service without planning the communication protocol. Claude will pause, outline the .proto files, define the interfaces, and then write the code.
The Security Elephant in the Room
We cannot talk about Codex 5.3 vs Claude Opus 4.6 without talking about the terrifying reality of giving an AI terminal access.
OpenAI has introduced “Guardian Rails” for Codex 5.3, preventing it from executing rm -rf / or accessing system-critical directories. However, the new cyber risks emerging from GPT-5.3-Codex are real.
- Prompt Injection: If an attacker can inject a prompt into your repo (via a malicious PR comment, for example), and your autonomous agent reads it, they could theoretically trick the agent into exfiltrating environment variables.
- Recursive Hallucination: Codex 5.3’s “fix it” loop can sometimes spiral. It might try to fix a dependency error by uninstalling half your system libraries if not sandbox-constrained.
Claude Opus 4.6, by virtue of being less “integrated” into the OS, offers a safer, albeit slower, sandbox. It writes the code, but you have to copy-paste it to the terminal. That friction is a security feature.

The trade-off between autonomy and security in Codex 5.3 vs Claude Opus 4.6.
The Cost of Autonomy
Pricing models are diverging.
- Codex 5.3: Tiered pricing based on “Compute Steps.” You aren’t just paying for tokens; you are paying for the CPU time the agent uses to run its verification loops. This makes it unpredictable. A simple bug fix could cost $0.05 or $5.00 depending on how many times the agent loops.
- Claude Opus 4.6: Standard token-based pricing. Expensive, but predictable.
For a deep dive on how this shifts the economic model of software dev, check out this analysis on GPT-5.3 Codex: The 10x Engineer.
The Verdict: Which One Do You Hire?
The choice between Codex 5.3 vs Claude Opus 4.6 comes down to your trust in autonomy.
Choose Codex 5.3 if:
- You have a robust sandbox environment (Docker containers are mandatory).
- Your tasks are iterative (debugging, refactoring, writing unit tests).
- Speed is your primary metric.
- You want to build “Agents” that do work while you sleep.
Choose Claude Opus 4.6 if:
- You are in the design/architecture phase.
- You are working with massive, monolithic codebases where context is king.
- You prefer a “Human-in-the-Loop” workflow for security reasons.
- You need deep reasoning over raw execution speed.
The Future is Agentic
Whether you choose the speed of Codex or the depth of Opus, one thing is clear: The days of manually typing every import statement are over. The bottleneck is no longer syntax; it’s strategy.
If you’re ready to stop coding and start architecting, but you don’t know how to wire these agents together, you need a roadmap. That’s exactly what we build in our AI Agents Without Programming course. We teach you how to orchestrate these models to do the heavy lifting, so you can focus on building the product, not fighting the linter.
The tools are here. The question is, are you brave enough to give them the keys to the terminal?

